 10955
10955
EasyCTF 2018 - Special Endings (Forensic)
Voici la write-up pour le challenge Special Endings du Easyctf IV par switch et Bcsadmin pour Beerznhash.
Le challenge a été partiellement résolu par Bcsadmin mais lorsqu’il m’a demandé de scripter l’obtention du flag on s’est rendu compte que quelque chose manquait à son raisonnement.
Le challenge était composé de plusieurs lignes en base64 qui donnaient des citations d’Ursula K. Le Guin (écrivaine américaine de scifi).
WW91IHdpbGwgZGllLiBZb3Ugd2lsbCBub3QgbGl2ZSBmb3JldmVyLm==
Tm9yIHdpbGwgYW55IG1hbiBub3IgYW55IHRoaW5nLiBOb3RoaW5nIGlzIGltbW9ydGFsLp==
QnV0IG9ubHkgdG8gdXMgaXMgaXQgZ2l2ZW4gdG8ga25vdyB0aGF0IHdlIG11c3QgZGllLm==
QW5kIHRoYXQgaXMgYSBncmVhdCBnaWZ0OiB0aGUgZ2lmdCBvZiBzZWxmaG9vZC7=
Rm9yIHdlIGhhdmUgb25seSB3aGF0IHdlIGtub3cgd2UgbXVzdCBsb3NlLCB3aGF0IHdlIGFyZSB3aWxsaW5nIHRvIGxvc2UuLi4=
VGhhdCBzZWxmaG9vZCB3aGljaCBpcyBvdXIgdG9ybWVudCwgYW5kIG91ciB0cmVhc3VyZSwgYW5kIG91ciBodW1hbml0eSwgZG9lcyBub3QgZW5kdXJlLm==
SXQgY2hhbmdlczsgaXQgaXMgZ29uZSwgYSB3YXZlIG9uIHRoZSBzZWEu
V291bGQgeW91IGhhdmUgdGhlIHNlYSBncm93IHN0aWxsIGFuZCB0aGUgdGlkZXMgY2Vhc2UsIHRvIHNhdmUgb25lIHdhdmUsIHRvIHNhdmUgeW91cnNlbGY/
LSBVcnN1bGEgSy4gTGUgR3VpbiwgVGhlIEZhcnRoZXN0IFNob3Jl
...
Lorsqu’on décodait le base64 puis que l’on le réencodait on obtenait une valeur différente

Le dernier caractère passe de m à g. Une fois mis sous la forme binaire la différence sautait aux yeux et le titre du chall prenait tout son sens
.png)
Les 4 derniers bits du base64 donné ont été modifiés. Pour comprendre la suite du challenge il était nécessaire de lire la RFC du base64
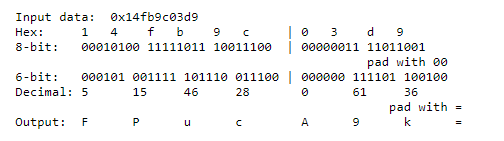
Pour passer en format base64, la représentation binaire des données à encoder est séparée en bloc de 6 bits. Une fois séparé chaque petit bloc se voit attribué un des 63 caractères en fonction du chiffre binaire obtenu. La concaténation de chaque caractère donne la donnée représentée en base64.
Maintenant que se passe-t-il lorsque il y a un nombre impaire de bits ? C’est à dire que le dernier paquet contient moins de 6 bits comme dans ce cas :
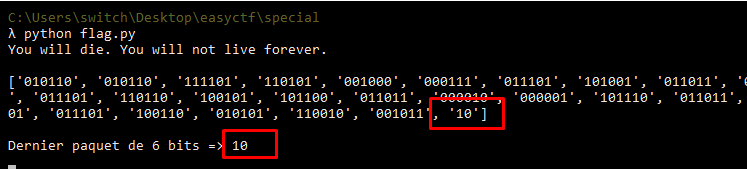
La réponse est simple : on rajoute autant de 0 que nécessaire pour arriver à 6 bits. Cela explique le résultat obtenu dans la deuxième image. Après le ‘10’ sont rajoutés 4 ‘0’.
C’est ces X ‘0’ correspondant au padding qui ont été modifiés par une donnée différente, 0110 pour l’exemple suivant :
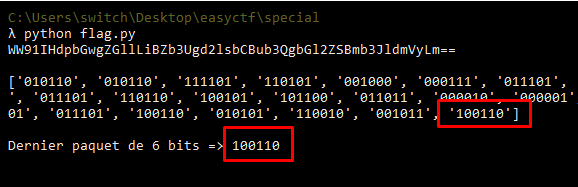
A ce moment notre logique est la suivante :
-
Récupérer le padding correspondant nécessaire pour l’encodage d’une phrase
-
Extraire les X derniers bits du base64 modifié
-
Concaténer tous ses bits puis récupérer leur représentation ASCII censé nous donner le flag
Su le papier ça parait clean, pas difficile à coder sauf que :

Le flag trouvé possède des chars non imprimables. Nous sommes restés à cet endroit un certain moment, jusqu’à que je comprenne notre erreur.
Nous récupérions le padding modifié uniquement pour les phrases qui, lorsqu’elles étaient réencodées, donnaient une valeur différente. Cette nouvelle valeur était causée par un padding contenant autre chose que des ‘0’.
Mais si la valeur modifiée contenait uniquement des ‘0’ ? La valeur de padding aurait été identique (et donc un même encodage) !
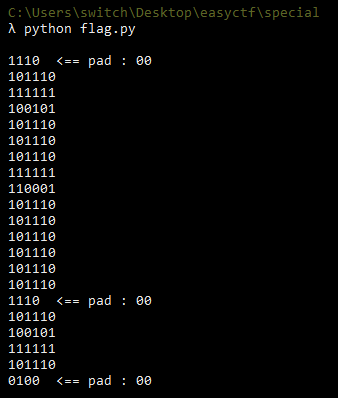
En ajoutant ces trois ‘00’ aux autres valeurs de padding récoltées on obtenait une toute autre valeur !

Code
#!/usr/bin/python
from base64 import b64encode, b64decode
dictio = {"000000" : "A", "010001" : "R", "100010" : "i", "110011" : "z", "000001" : "B", "010010" : "S", "100011" : "j", "110100" : "0", "000010" : "C", "010011" : "T", "100100" : "k", "110101" : "1", "000011" : "D", "010100" : "U", "100101" : "l", "110110" : "2", "000100" : "E", "010101" : "V", "100110" : "m", "110111" : "3", "000101" : "F", "010110" : "W", "100111" : "n", "111000" : "4", "000110" : "G", "010111" : "X", "101000" : "o", "111001" : "5", "000111" : "H", "011000" : "Y", "101001" : "p", "111010" : "6", "001000" : "I", "011001" : "Z", "101010" : "q", "111011" : "7", "001001" : "J", "011010" : "a", "101011" : "r", "111100" : "8", "001010" : "K", "011011" : "b", "101100" : "s", "111101" : "9", "001011" : "L", "011100" : "c", "101101" : "t", "111110" : "+", "001100" : "M", "011101" : "d", "101110" : "u", "111111" : "/", "001101" : "N", "011110" : "e", "101111" : "v", "001110" : "O", "011111" : "f", "110000" : "w", "001111" : "P", "100000" : "g", "110001" : "x", "010000" : "Q", "100001" : "h", "110010" : "y"}
data = open("file.txt", "r").read().split("\n")
data = [data for data in data if data != ""]
def split(line, n):
return [line[i:i+n] for i in range(0, len(line), n)]
def text_to_6bits(text):
n = 6
line = ''.join('{0:08b}'.format(ord(x), 'b') for x in text)
return split(line, n)
def return_pad(bits):
return 6 - len(bits[-1])
def b64_to_6bits(b64):
return "".join([dictio.keys()[dictio.values().index(char)] for char in b64 if char != "="])
pad_ag = ""
for phrase in data:
if phrase != b64encode(b64decode(phrase)):
decoded = b64decode(phrase)
bits = text_to_6bits(decoded)
padded = b64_to_6bits(phrase)
n = return_pad(bits)
pad = padded[-n:]
pad_ag += pad
else:
decoded = b64decode(phrase)
bits = text_to_6bits(decoded)
n = return_pad(bits)
if n == 2:
pad_ag += "00"
msg = ""
for char in split(pad_ag, 8):
msg += chr(int(char, 2))
print msg